1 Reliable UDP Algorithms
This document is a survey of various algorithms intended for adding reliable delivery to the user datagram protocol.
1.1 UDP Characteristics
The UDP protocol is an extremely simple protocol that allows for the sending of datagrams over IP. UDP is preferable to TCP for the delivery of time-critical data as many of the reliability features of TCP tend to come at the cost of higher latency and delays caused by the unconditional re-sending of data in the event of packet loss.
In contrast to TCP, which presents the programmer with one ordered octet stream per connected peer, UDP provides a packet-based interface with no concept of a connected peer. Datagrams arrive containing a source address1, and programmers are expected to track conceptual peer “connections” manually.
TCP guarantees2 that either a given octet will be delivered to the connected peer, or the connection will be broken and the programmer notified. UDP does not guarantee that any given packet will be delivered, and no notification is provided in the case of lost packets.
TCP guarantees that every octet sent will be received in the order that it was sent. UDP does not guarantee that transmitted packets will be received in any particular order, although the underlying protocols such as IP imply that packets will generally be received in the order transmitted in the absence of routing and/or hardware errors.
TCP places no limits on the size of transmitted data. UDP directly exposes the programmer to several implementation-specific (but also standardized) packet size limits. Creating packets of sizes that exceed these limits increase the chances that packets will either be fragmented or simply dropped. Fragmentation is undesirable because if any of the individual fragments of a datagram are lost, the datagram as a whole is automatically discarded. Working out a safe maximum size for datagrams is not trivial due to various overlapping standards.
UDP datagrams are typically embedded within the bodies of IP packets and are therefore subject to limits defined within with IP standards. For example, the IPv4 RFC 791 states:
All hosts must be prepared to accept datagrams of up to 576 octets (whether they arrive whole or in fragments). It is recommended that hosts only send datagrams larger than 576 octets if they have assurance that the destination is prepared to accept the larger datagrams.
In IPV6, this limit was raised to 1500 octets:
A node must be able to accept a fragmented packet that, after reassembly, is as large as 1500 octets. A node is permitted to accept fragmented packets that reassemble to more than 1500 octets. An upper-layer protocol or application that depends on IPv6 fragmentation to send packets larger than the MTU of a path should not send packets larger than 1500 octets unless it has assurance that the destination is capable of reassembling packets of that larger size.
However, this value is again constrained in practice by the same RFC, which sets the minimum allowed maximum-transmission-unit (MTU) size to 1280:
Links that have a configurable MTU (for example, PPP links [RFC- 1661]) must be configured to have an MTU of at least 1280 octets; it is recommended that they be configured with an MTU of 1500 octets or greater, to accommodate possible encapsulations (i.e., tunneling) without incurring IPv6-layer fragmentation.
IPv4 packets have a header size in the range of [20, 60] octets. Therefore, assuming a worst-case maximum packet size of 576 octets, this leaves at most 576 - 20 = 556 and at least 576 - 60 = 516 octets available for expressing a UDP datagram. However, UDP datagrams have a mandatory 8 octet header, leaving at most (576 - 20) - 8 = 548 and at least (576 - 60) - 8 = 508 octets available for the actual content of the UDP datagram.
In practice, given the slow but steady adoption of IPv6, it can generally be assumed (as of the time of writing) that the majority of both consumer and corporate networking hardware is capable of supporting IPv6 and can therefore support the size limits mandated by IPv6 for IPv4 traffic.
IPv6 differs from IPv4 in that the basic headers of an IPv6 packet are fixed at 40 octets in size, with optional sender-controlled extension headers. For reasons of practicality then, it can be assumed that these extension headers will not be present and therefore each IPv6 packet can be assumed to have a fixed-size overhead of 40 octets.
Assuming a best-case size of 1500 octets and a worst-case size of 1280 octets for an IPv6 packet that can be transmitted without fragmentation, this leaves at most 1500 - 40 = 1460 and at least 1280 - 40 = 1240 octets available for expressing a UDP datagram. Given the size of the UDP header, this means a best-case maximum size of (1500 - 40) - 8 = 1452 and a worst-case maximum size of (1280 - 40) - 8 = 1232 octets available for the actual content of a UDP datagram.
As a consequence of the above limits, it can be inferred that it is more efficient to send fewer but larger packets. A single datagram sent with 1000 octets of user data may incur 48 octets of overhead by the underlying protocols. The same 1000 octets of user data sent as 10 separate datagrams may effectively incur 48 * 10 = 480 octets of overhead: Nearly half the size of the data itself! Additionally, sending a datagram will typically imply making a relatively costly call to the operating system. Making one system call is generally faster than making ten calls. Sending packets that are too large, however, will run the risk of fragmentation and/or dropped packets. Unfortunately, there is no way to know the implementation-specific limits of all the hardware that a packet may traverse between the sender and receiver, so the programmer is forced to rely on experimentation, conservative estimates, and/or adaptive application-defined protocols.
At the time of writing, software authors appear to be assuming a value of roughly 1200 octets for the content portion of UDP datagrams.
1.2 Conventions
In this document, communication is usually described in terms of a sender and a receiver, and in a manner that suggests that the communication is happening in a mostly one-way fashion from sender to receiver. This is simply for the purposes of making the algorithms easier to describe. It should be assumed that in practice, the same algorithm is being followed on both sides, providing simultaneous bidirectional communication.
1.3 Ordering
All of the reliable delivery algorithms described here implicitly depend on the delivered datagrams having well-defined ordered delivery semantics. Informally, this implies that if a sender sends a packet A followed by a packet B, then the receiver will receive A and then receive B (assuming that both packets actually arrive). As UDP itself explicitly does not guarantee ordered delivery, a fundamental step in providing reliable delivery is to ensure that packets arrive in the right order.
1.3.1 Sequence Numbers
The simplest approach to provide in-order delivery of datagrams is to assign each datagram a monotonically increasing sequence number.
Each peer stores an incoming sequence number i, and an outgoing sequence number o. o is incremented every time a packet is sent. When a packet is received, if i is less than or equal to the packet’s sequence number p, then i is set to p + 1 and the packet is delivered to the application. If i turned out to be greater than p, then this almost certainly indicates that packets have been delivered out of order, a packet has been lost, or a packet has been duplicated, and can simply be discarded.
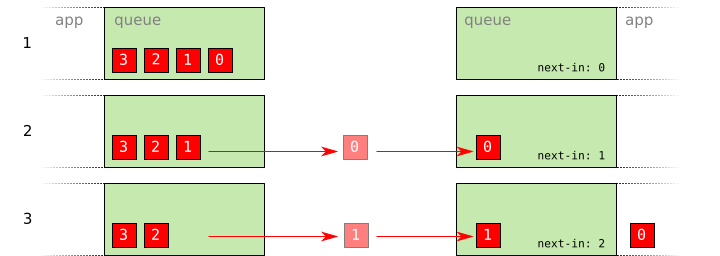
- No packets have been sent.
- Packet
0has been sent and has arrived. The packet’s sequence number is equal to the peer’s incoming sequence number. The peer’s sequence number is incremented. - Packet
0is delivered to the application. Packet1has been sent and has arrived, and the process continues.
Packet loss is treated correctly:
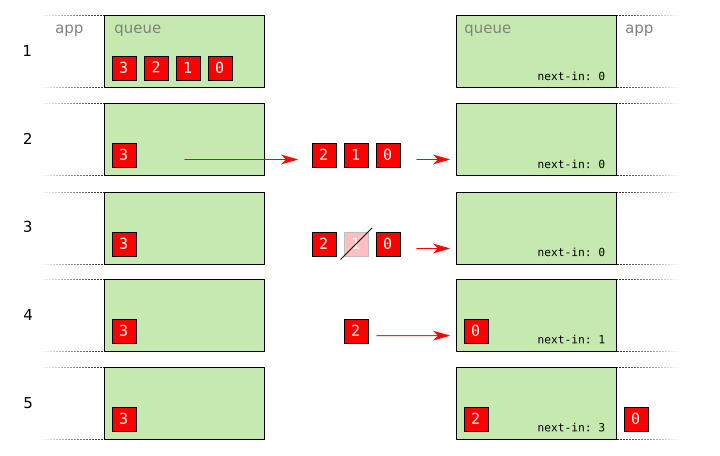
- No packets have been sent.
- Packets
2,1, and0have been sent. - In flight, packet
1is destroyed by an error on the network. - Packet
0arrives and is accepted by the sequence rules above. - Packet
2arrives and is also accepted. Note that the incoming sequence number on the peer ends up equal to3.
Packet duplication is also handled correctly:
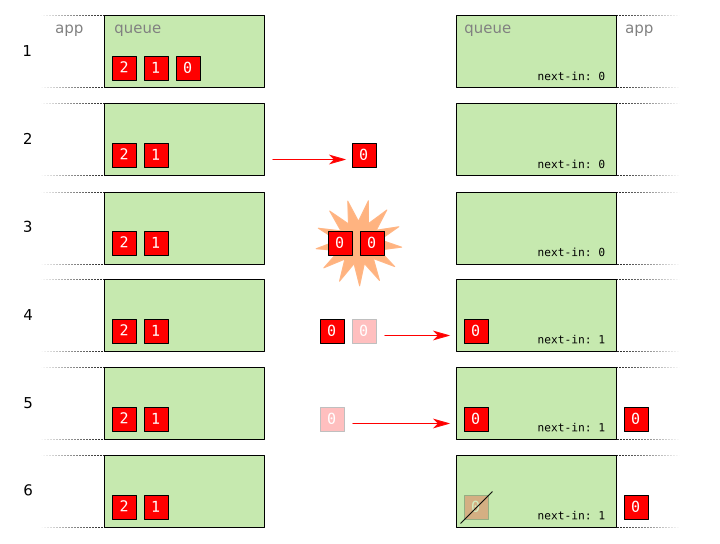
- No packets have been sent.
- Packet
0has been sent. - Packet
0is duplicated due to an error on the network. - The first instance of packet
0arrives and is accepted by the sequencing rules. - The second instance of packet
0arrives, but the incoming sequence number on the peer is now1… - The packet is discarded and the incoming sequence number stays the same.
Packet reordering is handled correctly, but in a slightly unsatisfactory manner:

- No packets have been sent.
- Packets
1and0have been sent. - Packets
1and0are reordered in flight due to an error on the network. - Packet
1arrives and is accepted by the sequencing rules. - Packet
0arrives… - Packet
0is discarded by the sequencing rules.
The problem here is that although packets 0 and 1 did arrive at the same time, the reordering caused packet 0 to be discarded unnecessarily. If the receiver is prepared to buffer messages, this problem can be alleviated by sorting the received packets in the buffer:
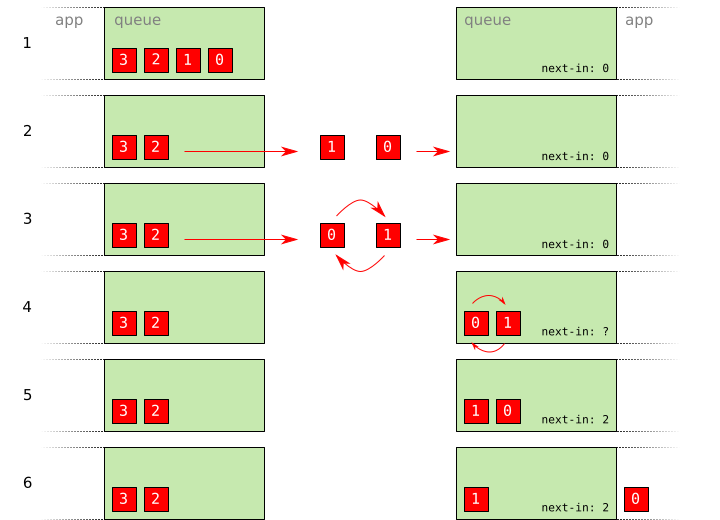
- No packets have been sent.
- Packets
1and0have been sent. - Packets
1and0are reordered in flight due to an error on the network. - Packets
1and0arrive, and are sorted by sequence number in the buffer. - The incoming sequence number is incremented according to the sequence number of the greatest received packet number.
- Packet
0is delivered, and the process continues.
However, this raises the further problem in that buffering naturally causes latency. Given that the assumption is that packets contain time-critical data, this is likely to be undesirable and buffering should probably be minimized.
1.3.2 Improved Sequence Numbers
One serious issue with this numbering approach is that a sequence number represented by a fixed-size unsigned integer will eventually wrap around to zero. At 60 packets per second, an unsigned 32 bit sequence number will take approximately 2.26 years to wrap around to zero. Additionally, bandwidth constraints will often force the use of a 16 bit sequence number. At 60 packets per second, an unsigned 16 bit sequence number will take approximately 18.2 minutes to wrap around to zero. When sequence numbers wrap, all newer packets will be erroneously discarded!
RFC 1982 defines a standard for serial number arithmetic. The general idea is to define a total ordering relation such that for integer types i of k bits, for all m and n of type i, m is considered less than n iff the signed distance between m and n is less than (pow 2 (k - 1)).
This can be implemented using simple two’s complement arithmetic. A 16-bit implementation in Haskell:
module SequenceNumber (T, initial, next, distance, from) where
import qualified Data.Word as DW
import qualified Data.Int as DI
newtype T =
SN DW.Word16
deriving Show
from :: Integer -> T
from = SN . fromInteger
initial :: T
initial = from 0
next :: T -> T
next (SN x) = SN $ x + (fromInteger 1)
distance :: T -> T -> Integer
distance (SN x) (SN y) =
let z = y - x
s :: DI.Int16
s = fromInteger (toInteger z) in
toInteger s
instance Eq T where
(==) x y = distance x y == 0This gives the following results:
> distance (from 0) (from 0)
0
> distance (from 0) (from 1)
1
> distance (from 0) (from 32767)
32767
> distance (from 0) (from 32768)
-32768
> distance (from 32767) (from 32768)
1
> distance (from 32768) (from 65535)
32767
> distance (from 32768) (from 65536)
-32768This gives the correct ordering behaviour as long as the difference between values remains less than (pow 2 (k - 1)). This reduces the problem of sequence numbering significantly: Rather than breaking down as soon as (pow 2 k) packets are received, the system instead works correctly as long as no more than (pow 2 (k - 1)) packets are received at a single instance in time. For the sake of example, assume that a receiver will buffer 1/60 seconds worth of packets before attempting to deliver them to an application. In practical terms, assuming that a malicious sender was deliberately trying to cause the sequence numbers to overflow by sending empty UDP datagrams, this would require the sender to send 32768 * (40 + 8) = 1572864 octets, or 1.572864 megabytes of data in roughly 1/60 seconds. This entails a transfer rate of roughly 1572864 * 60 = 94371840 octets per second, or 94.37184 megabytes. This is unlikely to occur on commodity hardware across the internet at the time of writing, but if this is still a concern, sequence numbers can simply be extended to 24 or 32 bits 3.
1.4 Guaranteed Delivery
1.4.1 ACK (Single send, single sequence)
A very simple algorithm for providing reliable delivery is to require acknowledgement for specifically flagged packets. If a packet p is flagged as reliable, the sender of p will not send any further packets until the receiver has responded with an acknowledgement packet that references the sequence number of p. If the sender has not received an acknowledgement for p within a configurable time limit, the sender re-sends p. Typically, the maximum number of re-sends is a configurable value. When the maximum number of re-sends has been reached without an acknowledgement, the receiver is considered to be unreachable and the application is notified. Often, an implementation will use an exponential backoff in the rate of re-sends under the assumption that packets are being lost due to network congestion, and therefore sending packets less frequently might help the congestion to clear.
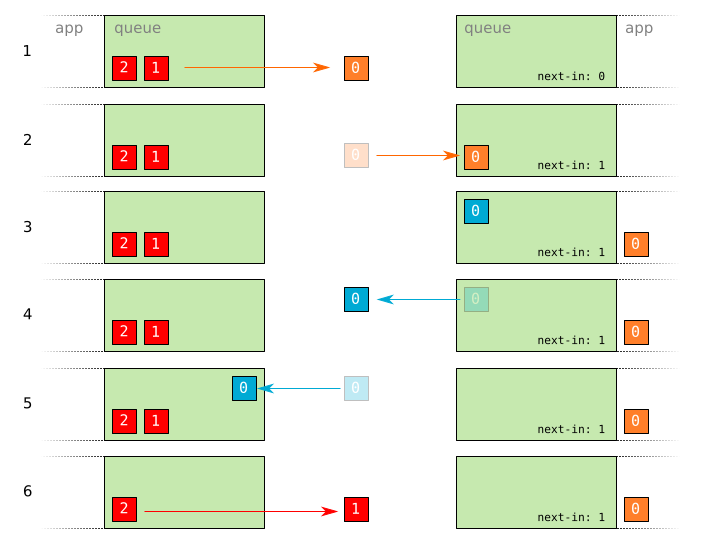
- A reliable packet
0is sent. - The reliable packet
0arrives. - An acknowledgement for
0is queued on the receiver. - The acknowledgement for
0is sent. - The acknowledgement for
0arrives.0is marked as having been received and the next packet is allowed to be sent. - Packet
1is sent.
While this approach has the advantage of simplicity, it suffers from several major issues.
Firstly, the main purpose of the whole system is to transmit time critical data. In the case of a lost reliable packet or acknowledgement, the sending of other packets is stalled until the reliable packet is delivered:
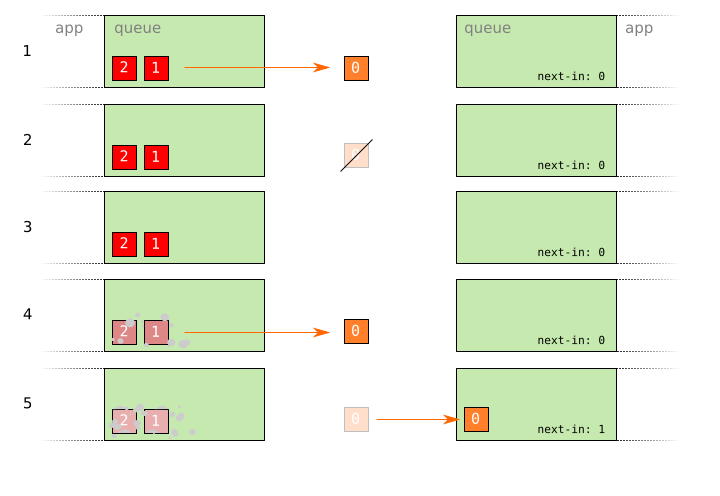
- A reliable packet
0is sent. - The packet
0is lost due to an error on the network. - The sender waits for an acknowledgement.
- The sender re-sends packet
0. The time critical data held in packets1and2begins to become stale. - The re-send of packet
0finally arrives at the receiver. The time critical data held in packets1and2has taken so long to send that it is now irrelevant. Worse, the sender must now wait for an acknowledgement from the receiver, delaying1and2even further.
The outcome is the same regardless of whether packet 0 is lost, or the acknowledgement is lost.
Secondly, the system assumes that there will be at most one reliable packet in flight at any given time. This effectively means that in the best case, the rate of sending for reliable packets (and then, by extension, the rate for any interleaved packets) is reduced to that of being equal to the round trip time (RTT). This is a serious problem for applications that need to send and receive a stream of packets at a very high rate.
1.4.2 ACK (Single send, independent sequencing)
One way to mitigate the issue of lost reliable packets stalling the delivery of unreliable packets is to sequence reliable and unreliable packets separately. In this case, the sender and receiver are divided up into two separate queues, with each queue having its own outgoing and incoming sequence numbers. Reliable packets are still sent one-at-a-time, with at most one reliable packet in flight at any given time.
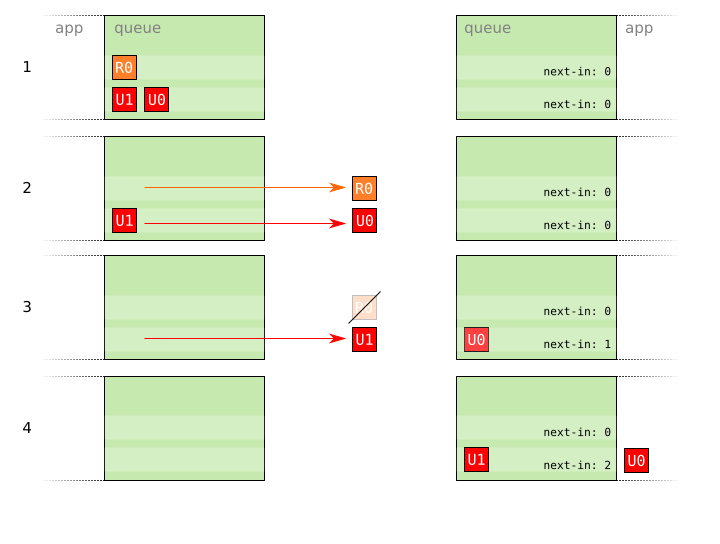
- A reliable packet
R0and two unreliable packetsU0andU1are prepared for sending. - The packets
R0andU0are sent. - Packet
R0is lost due to an error on the network, butU0arrives correctly. Meanwhile,R1has already been sent because it is independently sequenced toR0and therefore does not have to wait for an acknowledgement toR0before being sent. - The packet
R1arrives.
As mentioned, this solves the problem of lost reliable packets or acknowledgements stalling the delivery of unreliable packets, but the rate of sending for reliable packets is still limited by the need to wait for acknowledgement before the next packet can be sent.
Additionally, the fact that there are now separate queues for reliable and unreliable packets means that in-order delivery can no longer be guaranteed between a given reliable packet r and a given unreliable packet u. Regardless of the order that r and u are sent, either u or r may be received and delivered to the application first, as the sequence numbers are independent and so the original sending order is lost. However, this problem is fairly easily corrected by adding an extra global sequence number to all packets. This sequence number is ignored by the queues and is only used by the receiving application to reconstruct the original order of received packets.
1.4.3 ACK (Multi sending, single sequence)
The original single-send, single-sequence model can be extended by allowing multiple reliable packets to be in flight at any given time. Reliable and unreliable packets are not independently sequenced, but packets may be sent without waiting for any acknowledgement of previous packets.
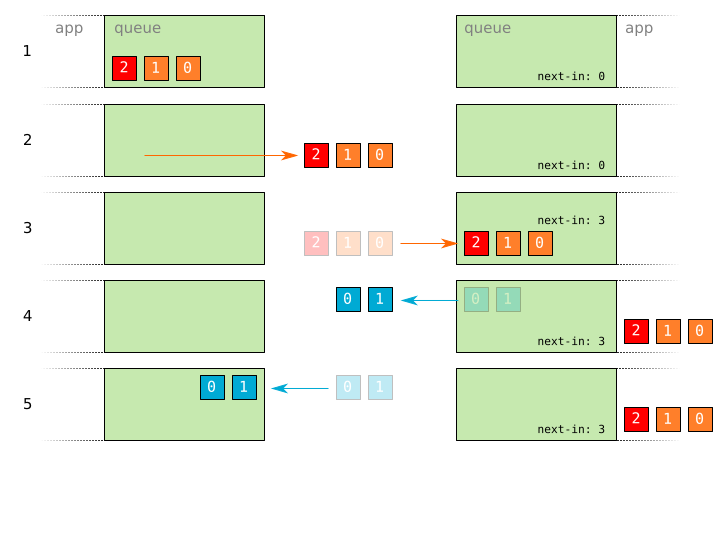
- Two reliable packets
0and1, and an unreliable packet2are prepared for sending. - The packets
0,1, and2are sent. - The packets
0,1, and2are received. - Acknowledgements for
0and1are sent. Meanwhile, all three packets have been delivered to the application. - The acknowledgements are received.
As simple as this change may seem, it introduces a fatal flaw with regards to the correct handling of packets. Consider, for example, the case of two reliable packets being delivered in the wrong order:
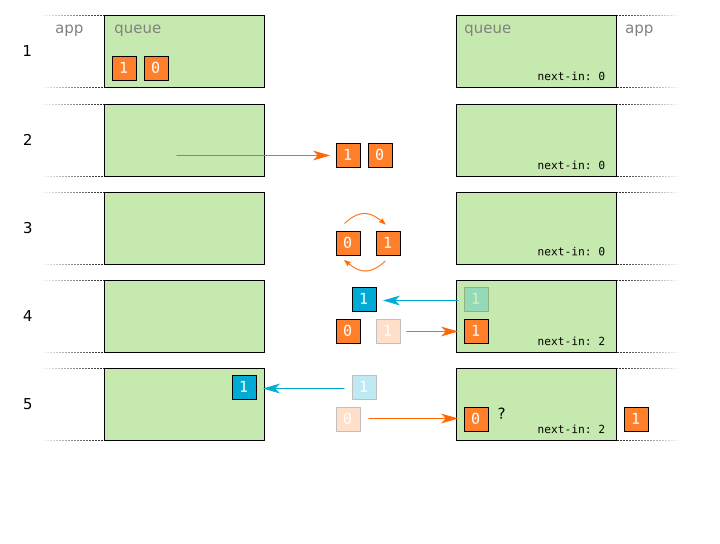
- Two reliable packets
0and1are prepared for sending. - The packets
0,1are sent. - The packets
0,1are reordered in flight due to an error on the network. - The packet
1reaches the receiver and is accepted, and an acknowledgement is sent. - The packet
0reaches the receiver.
At this point, there is a conflict with the original sequencing rules: The packet 0 has a lower sequence number than the one the receiver is now expecting, due to the accepted delivery of 1. The receiver should not discard the packet, because the packet is marked as reliable and should therefore have guaranteed delivery. The receiver cannot accept the packet without violating the sequencing rules. The receiver could also not have delayed the acceptance of 1: The receiver could have noticed the discontinuity in the sequence numbers when 1 arrived, and delayed delivery of 1 until 0 arrived. However, the receiver of course has no way to know that 0 was also a reliable packet. If 0 had been an unreliable packet, then the discontinuity in the sequence numbers could simply have been due to a lost packet and should therefore be ignored. The receiver cannot assume that 0 was a reliable packet, because otherwise it would be forced to wait perpetually for a packet that may not be coming. This problem applies equally if the 0 packet was simply lost: The sender would re-send 0 in short order, and the same conflict would result.
Thankfully, this fatal flaw can be mitigated by once again introducing independent sequencing.
1.4.4 ACK (Multi sending, independent sequence)
By once again introducing independent sequencing to unreliable and reliable packets in a slightly modified form, the conflict between the sequencing rules and having multiple reliable packets in flight can be resolved.
Specifically, by once again separating reliable and unreliable packets into their own queues, the receiver managing each queue has more information to work with when it notices a discontinuity in sequence numbers. If there is a discontinuity in the sequence numbers of an unreliable packet queue, it can simply be ignored: The packet was either lost, or if it was reordered in flight and will shortly show up, it can be safely discarded as with any late unreliable packet. If there is a discontinuity in the sequence numbers of a reliable queue, the receiver can assume that the missing packet will be resent by the sender shortly, and can delay the delivery of any already received reliable packets until that happens.
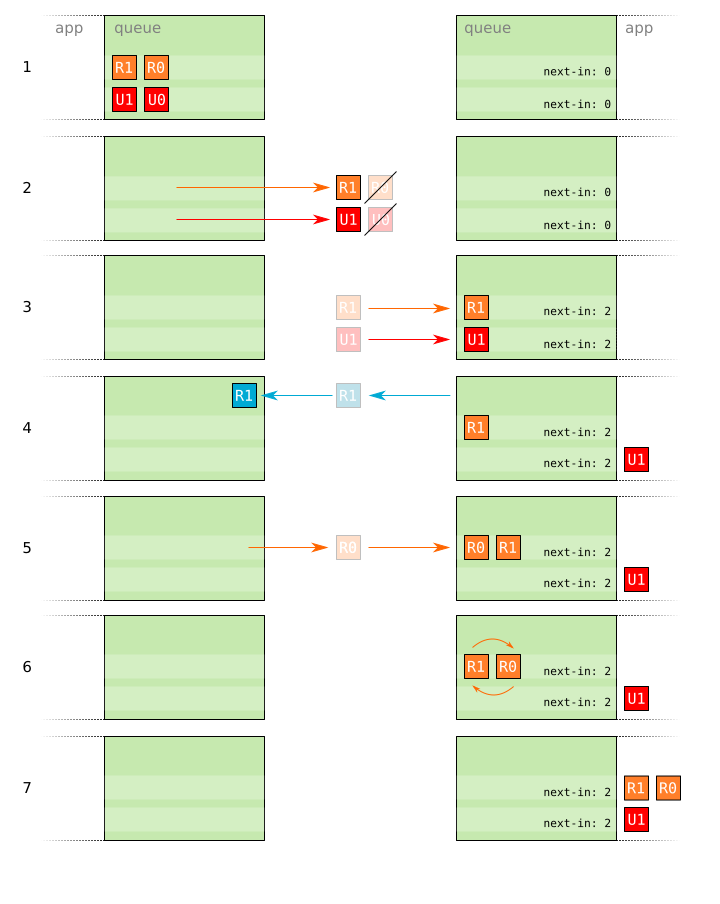
- Two reliable packets
R0andR1, and two unreliable packetsU0andU1, are prepared for sending. - All of the packets are sent, but packets
R0andU0are lost in flight. - Packets
R1andU1arrive at the receiver. - The receiver notices a discontinuity in the sequence number for
U1, but asU1is an unreliable packet, it simply considersU0to have been lost and deliversU1to the application. The receiver sends an acknowledgement forR1but stalls delivery of the packet until the missingR0packet has arrived (which it can infer must exist due to the discontinuity in the sequence number). - The sender re-sends
R0because it has not received any acknowledgment for theR0packet from the receiver, and it arrives safely. - The stalled
R1and re-sentR0packets are reordered in the queue according to their sequence numbers. R0andR1are delivered to the application.
The multi-send, independent-sequencing approach is used by the enet package.
1.4.5 NACK
The negative ACK model takes an optimistic approach to packet delivery. Specifically, it assumes that all packets are being delivered correctly, and requires the receiver to request that the sender re-send any missing packets.
To implement negative ACKs, reliable and unreliable packets must be independently sequenced. If the receiver notices a discontinuity in the sequence numbers of unreliable packets, it ignores it. If the receiver notices a discontinuity in the sequence numbers of reliable packets, it stalls delivery of any pending reliable packets to the application and sends a negative acknowledgement to the sender containing the sequence number(s) of any missing packets that need to be re-sent.
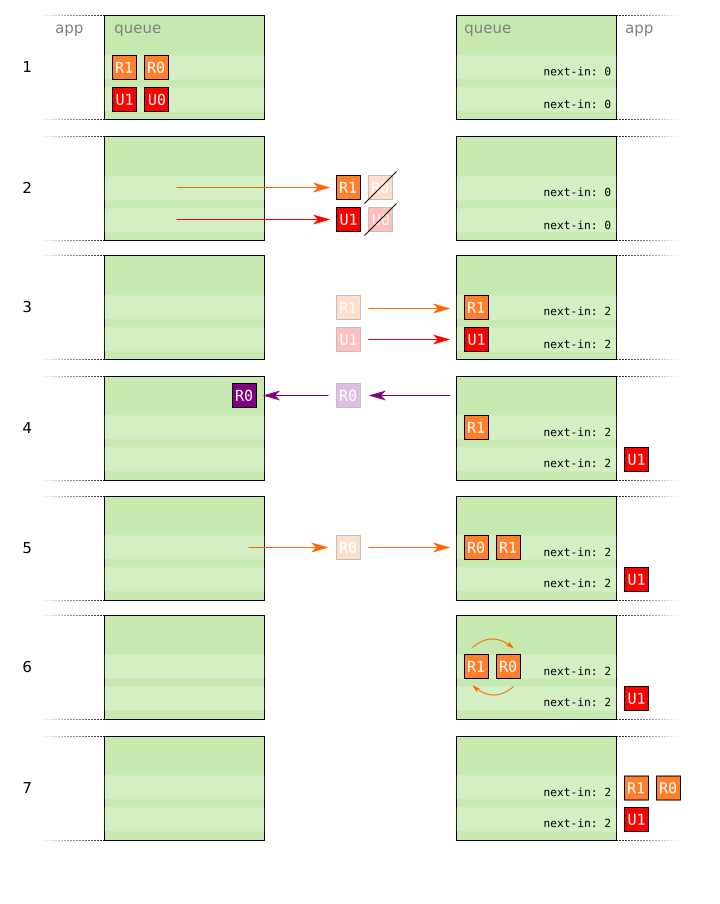
- Two reliable packets
R0andR1, and two unreliable packetsU0andU1, are prepared for sending. - All of the packets are sent, but packets
R0andU0are lost in flight. - Packets
R1andU1arrive at the receiver. - The receiver notices a discontinuity in the sequence number for
U1, but asU1is an unreliable packet, it simply considersU0to have been lost and deliversU1to the application. The receiver notices a discontinuity in the sequence number forR1and so sends a negative acknowledgement requesting thatR0be re-sent. - The sender re-sends
R0and it arrives. - The stalled
R1and re-sentR0packets are reordered in the queue according to their sequence numbers. R0andR1are delivered to the application.
Of course, it is possible for negative acknowledgement packets to be lost in flight. However, the exact same procedure is followed for the sending of negative acknowledgements as with re-sending unacknowledged packets in positive ACK systems. The negative acknowledgement packet is re-sent up to a maximum number of times (possibly with an exponential backoff). If the requested packet is not received within this time, the sender is considered to be defective or dead and the application is notified.
The advantage of the negative ACK approach is that it is lighter on bandwidth use: Only packets that did not arrive cause an extra packet to be sent. In contrast, positive acknowledgement systems require an acknowledgement packet for every reliable packet.
A disadvantage of the negative ACK approach is that the sender must keep a copy of every reliable packet sent for an indefinite amount of time; the receiver may theoretically request a re-send of any packet ever sent by the sender4. In practice, many negative ACK systems equip reliable packets with a time-to-live value, and the receiver cannot request re-sends of packets that are older than the agreed time-to-live value. This allows the sender to avoid having to keep copies of packets around forever just in case the remote side requests them. Adding a time limit does have the unfortunate side effect that reliable packets are then no longer really reliable packets; they are simply packets that will be re-sent until a maximum time limit is exceeded.
1.4.6 Redundant ACK
All of the systems described so far are able to operate under the assumption that packets are sent at a variable rate, as and when they are needed. For example, a simple realtime strategy simulation may only exchange packets with a server when the player actually executes orders. For the rest of the time, the client and server may only be exchanging the occasional message to measure round-trip-times, for example.
The redundant ACK approach, designed by Glenn Fiedler, can be used when the application is such that the sender and receiver are exchanging an unbroken stream of packets at a relatively high fixed rate (such as 60 packets per second). This is often the case in fast-paced realtime action games and/or video conferencing.
The approach uses the standard improved sequence numbers for packets, but does not explicitly categorize packets as reliable or unreliable. Instead, each packet sent from the sender to the receiver contains the sequence number r of the packet received most recently from the receiver. In addition to this, each packet contains a fixed-size bitfield of n bits, where for each i such that 0 < i <= n, bit i is set to true if a packet with sequence number r - i has been received. Essentially, it is a very space-efficient method for automatically including redundant acknowledgements for the last n received packets, inside every single packet exchanged. Given the assumption that packets are being exchanged at a fixed rate, if the acknowledgement bitfields in n received packets all state that a given packet has not been received, it can be stated with a high degree of confidence that the packet was not received. The author gives the example of a client and server exchanging packets at a rate of 30 packets per second: With a field of 32 bits, if an acknowledgment is not received in any of the packets received over the course of one second, it is very likely that the packet was lost.
The protocol also states that packets are never re-sent. Instead, the redundant acknowledgements in the protocol simply provide a way for applications to be notified that any arbitrary packet was not received by the receiver. If the lost packet contained time-critical disposable data by the application, the notification can be ignored. If the packet was assumed to contain data that needed reliable delivery, the contents of the old packet can be sent again as a new packet. Of course, because old data is being sent anew, the application is again required to assign an application-specific sequence number to the data, because the packet sequence numbers no longer match the logical order of the data.
The source address can be trivially forged by the sender, or by any node between the sender and the receiver.↩︎
With some exceptions: http://blog.h2o.ai/2013/08/tcp-is-not-reliable/↩︎
Overflowing
24bit sequence numbers entails sending8388607 * (40 + 8) = 402653136octets in1/60seconds, or402.65314megabytes. That’s24.159188gigabytes per second.32bit sequence numbers would require2147483647 * (40 + 8) = 103079215056octets in1/60seconds, or103.07922gigabytes. That’s6184.7532gigabytes per second. It may be some time before32bit sequence numbers are necessary.↩︎Modulo practical limits such as not actually being able to refer to very old sequence number due to the eventual wrapping and re-use of sequence numbers.↩︎